Isograph one-pager
A whirlwind tour of Isograph.
The problem: efficient data fetching
Currently, in web/app dev, you want to: fetch all the data in one go, avoid underfetching (i.e. fetch everything that is needed) and avoid overfetching (don't fetch things that are unused.) These are hard, and avoiding overfetching is particularly difficult to maintain as an app changes.
Consider, for example, that a PM asks you to avoid using a field in a subcomponent: not using that field is easy, but removing it from the query is hard. You have to trace where that data goes and determine whether it flows into any other subcomponent. And you have to worry about that field flowing into a subcomponent in a way that isn't tracked by the type system. This is further compounded if the subcomponent is used across multiple screens, or your query takes the form of a REST endpoint and now you must contend with multiple versions of your app.
If you remove the field and it turns out to be used, you break the app. So, over time, queries tend to accumulate probably-unused fields.
How Isograph solves this
The fundamental building block in Isograph is a function from some (statically analyzable) graph data to an arbitrary value, called a client field. Client fields depend on fields (i.e. the graph data), and themselves define a field in the graph, and thus can depend on each other. So, Isograph apps are built of trees of client fields.
Note the syntax highlighting! Goto definition, hover, etc. also work.
There is a compiler (written in Rust) that scans your codebase and generates queries for exactly the server fields that are accessible from a root client field. (It generates a lot of other files, too.)
Thus, changes to the data required by any subcomponent (a client field) are automatically, correctly reflected in the correct queries.
How do I render a screen?
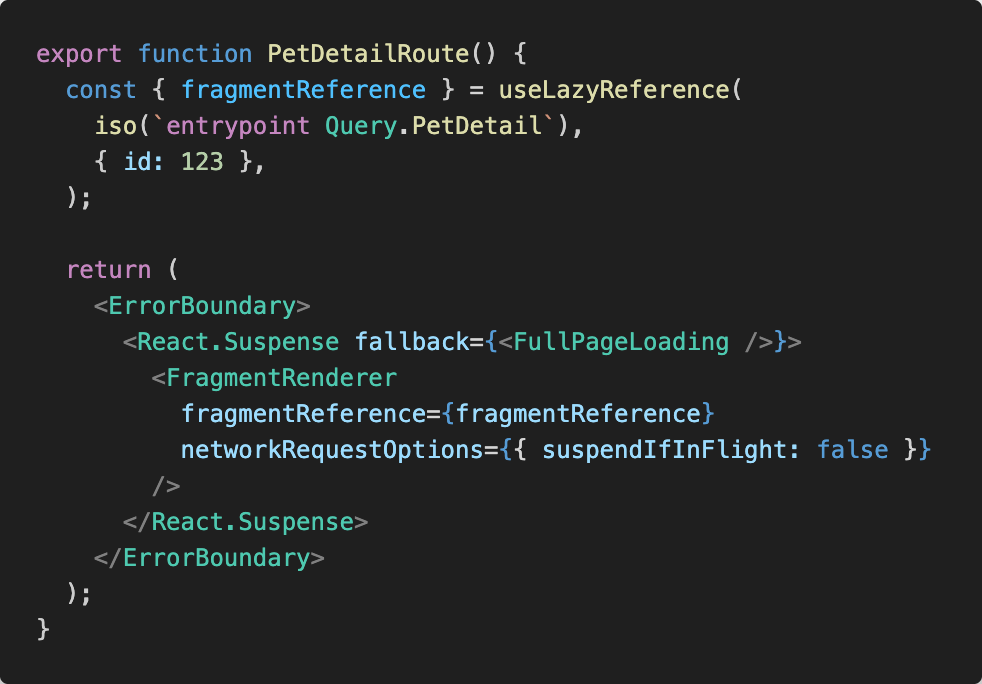
Let's say we have Query.PetDetail, which renders Pet.Avatar. The PetDetail component is an entrypoint, which is to say, the Isograph compiler has been instructed to generate a query for all the server fields reachable from Query.PetDetail. (This might be something like query PetDetail($id: ID!) pet(id: $id) { picture }).
A React component (call it PetDetailRoute) will use an Isograph API (like useLazyReference, which makes that network request during the initial render of a component) to fetch the data associated with that entrypoint. PetDetailRoute, when initially rendered, will suspend while that network request is in flight. When that request completes, it will re-render, and Isograph will render the Query.PetDetail component, which will render the Pet.Avatar component.
Throughout this, PetDetail does not pass any data down to Avatar! It simply receives a component that it can render.
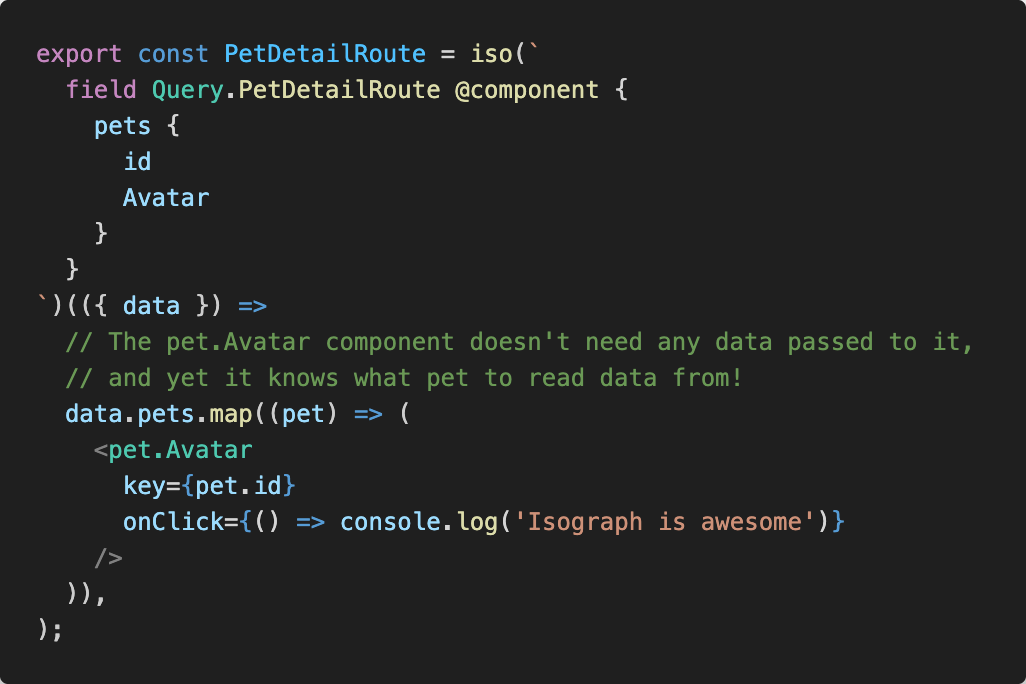
Client fields are a powerful primitive
In Isograph, the function that consumes the data and the data are statically linked, a rarity among these frameworks. This allows for many things:
- This vastly improves discoverability. How many
UserAvatarcomponents are in your codebase? With Isograph, in VSCode, you can just goto definition onUser.Avatarand see the implementation; when we add autocomplete functionality, you will be even more strongly discouraged from re-inventing duplicate components. - Deferring fetching some data? You should probably asynchronously loading the JS. In other frameworks, that's two unrelated steps; in Isograph, it's one. (This feature is called loadable fields.)
- Note that this is true for something like a comment component, whose data you fetch immediately, but as a separate request, as well for things like modals, whose data you may fetch only when the modal is shown.
- This is on the roadmap. But you can consider loadable fields as multiple queries that are syntactically related, but in practice distinct queries. We can do a lot with this, namely: avoid fetching data that is part of the loadable field query if we know it was fetched as part of the parent query!
- Example: So, in practice, this means that if you have an "above the fold" component (the blog details) and a deferred "below the fold" component (the comment list), then adding a field to the blog details component may result in that field being removed from the comment list component! How cool is that! And how impractical would that be to do manually.
- Also on the roadmap. We want to add the ability to execute client fields on the server (consider e.g. a
fullNamefield which concatenates first and last names.) To the caller (e.g. theUser.Avatar), thefullNamefield is a string. It's completely agnostic about whether it is executed on the client or server-executed.- Compare this to react server components, where only the "outer layer" can be server-rendered. Here, we have more precision about what is server-executed.
fullNamemight be an input to many components. Unlike with RSC, you can naturally have both interactive components and server execution of inputs.
- Compare this to react server components, where only the "outer layer" can be server-rendered. Here, we have more precision about what is server-executed.
These features listed above would be separate features in many frameworks, but they are essentially one feature in Isograph.
Isograph does a lot more for stability and perf
As mentioned previously, the Isograph compiler generates a lot of files. These files:
- contain queries for exactly the reachable server fields
- contain generated types
- contains data structures that the runtime uses to wire your app up together
One of those data structures is a reader AST, which describes the fields selected by a given client field. For example, picture in the Pet.Avatar component pictured above.
This reader AST is used for two things:
- Stability: the reader AST is used to read out just the fields selected by a given client field. So the network response may contain the pet's name, picture, cuteness, etc., but the avatar will receive just the picture. This is great for stability: changes to other client fields' selection sets may affect what the network response, but will not affect what is passed at runtime to the avatar, giving apps built with Isograph a level of stability unachievable by most other frameworks.
- Perf: the reader AST is used to set up subscriptions to exactly the fields that were read. So, if the pet's cuteness increases, the avatar will not re-render. Thus, apps built with Isograph stay performant, even with hundreds of components on the screen.
GraphQL? JavaScript? React?
Isograph is currently focused on GraphQL + JavaScript + React. However, these are all implementation details.
First on the chopping block is GraphQL. The user doesn't write GraphQL. The query that is sent to the backend is an opaque string (or an ID). So, it should be a fairly trivial change (and we are ready to do it) to generate, for example, SQL or tRPC or what-have-you. The overall workflow would be:
- we generate queries at build time. Get the hash of those queries, which acts as an ID.
- that ID is included in the generated files. The client sends that ID to the backend.
- the backend looks up the query text in a hashmap, and executes that query, and sends the result to the front-end.
Misc. runtime
Isograph does a lot more!
- There is another primitive, client pointers, which are functions from graph data to an ID.
- There is a state-of-the-art (to my knowledge, unsurpassed in DevEx + safety) method of modifying local data.
- Features, like pagination, whose details are hard to get right, are trivial with Isograph.